

Photo by Fallon Michael on Unsplash
NextRead version 2: Smarter author name search using AWS Comprehend
From scraping two-word author names in blocks of text, to better results using natural language processing


Table of contents
- Three major changes in NextRead version 2:
- Switching From Terraform to AWS Serverless Application Model for IaC
- Reduce code: Condensing multiple Lambda functions into a single function inside my State Machine
- Python has the upper hand over Amazon States Language (ASL) for string manipulation/data structure features
- How the NextRead State Machine works
- Current Issues with NextRead
Disclaimer: This personal blog post is not related to my current job with NIWC Atlantic or the Department of Navy whatsoever.
Please check out my previous article How I Created NextRead for more background information about this project. This blog post highlights the changes made in version 2. Please try out NextRead here.
Three major changes in NextRead version 2:
Building out my AWS infrastructure, I wanted to switch to Serverless Application Model (SAM) from Terraform.
I had a feeling that I could have done a better job of finding potential names in large blocks of text. AWS Comprehend API ability as a Natural Language Processing service was my solution.
Reduce code as much as possible for a smaller attack surface and be easier to maintain.
Switching From Terraform to AWS Serverless Application Model for IaC
For this project, I wanted to switch up and try out the AWS Serverless Application Model (SAM) CLI as a GitHub Action. Below I wanted to show the relevant snippets of code from my YAML files from my GitHub workflows, as well as a portion of my SAM template which built my AWS state machine for this project.
First up is my YAML file for my GitHub workflow using SAM CLI to deploy AWS infrastructure. Building and deploying infrastructure with Terraform and SAM are fairly similar, however, I prefer writing/reading YAML over HCL.
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: aws-actions/setup-sam@v2
with:
use-installer: true
- uses: aws-actions/configure-aws-credentials@v4
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: us-east-2
- run: sam build --use-container
env:
SAM_CLI_TELEMETRY: 0
- run: sam deploy --no-confirm-changeset --no-fail-on-empty-changeset
env:
SAM_CLI_TELEMETRY: 0
Second, a snippet of another GitHub workflow YAML file to copy my front-end HTML and JavaScript files to my public S3 bucket only if there is a push to either file in my GitHub repository:
on:
push:
paths:
- nextread.html
- assets/js/books.js
jobs:
Build_and_Upload:
permissions:
actions: write
contents: write
runs-on: ubuntu-latest
steps:
#... More code here
- name: 'Upload to S3 Bucket'
run: |
aws s3 cp nextread.html s3://${{ secrets.AWS_S3_FRONT_END_BUCKET_NAME }}
aws s3 cp assets/js/books.js s3://${{ secrets.AWS_S3_FRONT_END_BUCKET_NAME }}/assets/js/
#... More code here
Finally, below is a snippet of my SAM template which builds out my State Machine for NextRead. SAM made it easy to write a serverless function and extend it with direct CloudFormation resources since I had slightly advanced API Gateway methods I needed to write that required it. I appreciate using SAM which builds CloudFormation resources for you using best practices, while also allowing you to build out CloudFormation resources as well:
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: next-read
Resources:
NextReadStateMachine:
Type: AWS::Serverless::StateMachine
Properties:
Type: EXPRESS
DefinitionUri: statemachine/next_read.asl.json
DefinitionSubstitutions:
NewNextReadArn: !GetAtt NewNextReadFunction.Arn
ApiEndpoint: !Sub "${NextReadApi}.execute-api.${AWS::Region}.amazonaws.com"
Policies:
- LambdaInvokePolicy:
FunctionName: !Ref NewNextReadFunction
- ComprehendBasicAccessPolicy:
FunctionName: !Ref NewNextReadFunction
NewNextReadMethod:
Type: AWS::ApiGateway::Method
Properties:
AuthorizationType: NONE
MethodResponses:
- ResponseParameters:
method.response.header.Access-Control-Allow-Origin: true
ResponseModels:
application/json: !Ref ApiGatewayModel
StatusCode: "200"
HttpMethod: POST
ResourceId: !Ref NewNextReadResource
RestApiId: !Ref NextReadApi
Integration:
IntegrationHttpMethod: POST
Type: AWS
Credentials: !GetAtt ApiGatewayStepFunctionsRole.Arn
Uri: !Sub arn:aws:apigateway:${AWS::Region}:states:action/StartSyncExecution
PassthroughBehavior: WHEN_NO_TEMPLATES
RequestTemplates:
application/json: !Sub
- |-
#set($input = $input.json('$'))
{
"stateMachineArn": "${StateMachineArn}",
"input": "$util.escapeJavaScript($input)"
}
- { StateMachineArn: !Ref NextReadStateMachine }
IntegrationResponses:
- StatusCode: "200"
ResponseParameters:
method.response.header.Access-Control-Allow-Origin: "'https://matthewsechrist.cloud'"
ResponseTemplates:
application/json:
"#set ($parsedPayload = $util.parseJson($input.json('$.output')))
$parsedPayload"
#... More code here
Reduce code: Condensing multiple Lambda functions into a single function inside my State Machine
My guiding principle for version 2 of NextRead was to reduce as much code as possible. I love this quote from Jeff Atwood, a software engineer who co-founded Stack Overflow:
"...the best code is no code at all. Every new line of code you willingly bring into the world is code that has to be debugged, code that has to be read and understood, code that has to be supported. Every time you write new code, you should do so reluctantly, under duress, because you completely exhausted all your other options."
-Jeff Atwood
The biggest change made in version 2 was incorporating Amazon Comprehend API inside my State Machine. I switched the simplistic Python code I wrote for searching for potential author names in large blocks of text, to processing text through the Amazon Comprehend API. This in turn resulted in leaner, more secure code from 350 lines of front-end JavaScript code down to 130 lines.
The below snippet of my state machine ASL code shows how I extracted out an array of People's names that in a later task would check to see if they were an author from a Google Books API query. This snippet alone saved me from needing as many state changes in my state machine, along with bringing back more accurate results of potential authors.
Once I read Using JSONPath effectively in AWS Step Functions and learned how ASL uses the same syntax, I was set. All I needed to do was filter down my entities list from AWS Comprehend searching for entities with a Type of Person and a Score (level of confidence) higher than 85%.
//... More code here
"Type": "Task",
"Parameters": {
"LanguageCode": "en",
"Text.$": "$.description"
},
"Resource": "arn:aws:states:::aws-sdk:comprehend:detectEntities",
"ResultSelector": {
"potential_author.$": "$..Entities[?(@.Type==PERSON && @.Score > .85)].Text"
},
"End": true,
"OutputPath": "$.potential_author"
//... More code here
Python has the upper hand over Amazon States Language (ASL) for string manipulation/data structure features
While I appreciate and use intrinsic functions for AWS Step Functions, here are four things I found difficult/slow in ASL, but much easier to handle with Python:
Upper case to title case String Manipulation - Changing author names to title case looks better in my results.
Removing specific leading characters in Strings - The entities returned from AWS Comprehend would return leading dashes and other special characters before author names that I needed to remove.
Unique array of author names - Recreating entity uniqueness inherent in Python dictionaries is also difficult with ASL tasks, as arrays in ASL are not unique.
In less than 10 lines of Python code, I can pass in a JSON array of valid author names along with their first book's ISBN, and build a Python dictionary where the key is the ISBN value, and the author's name is the value. This forces unique author name values whereas in NextRead version 1 my results showed the author's name was spelled slightly differently (e.g. Matthew Sechrist vs. Matt Sechrist).
Finally, when I return the Python dictionary, I change any author's name in all uppercase to title case (e.g. it converts MATTHEW SECHRIST into Matthew Sechrist). I assume the risk of names that do not follow this convention displaying incorrectly (e.g. last of McKinty mistakenly shown as Mckinty).
def next_read(event, context):
author_dictionary = {}
for author in event['author']:
if (author['Name'].startswith(('-','–','.',' ','“','"','\''))) :
author_dictionary[author['first_author_book']] = author['Name'][1:]
else :
author_dictionary[author['first_author_book']] = author['Name']
return {"authors" : list({value.title() if value.isupper() else value for value in author_dictionary.values()}) }
How the NextRead State Machine works
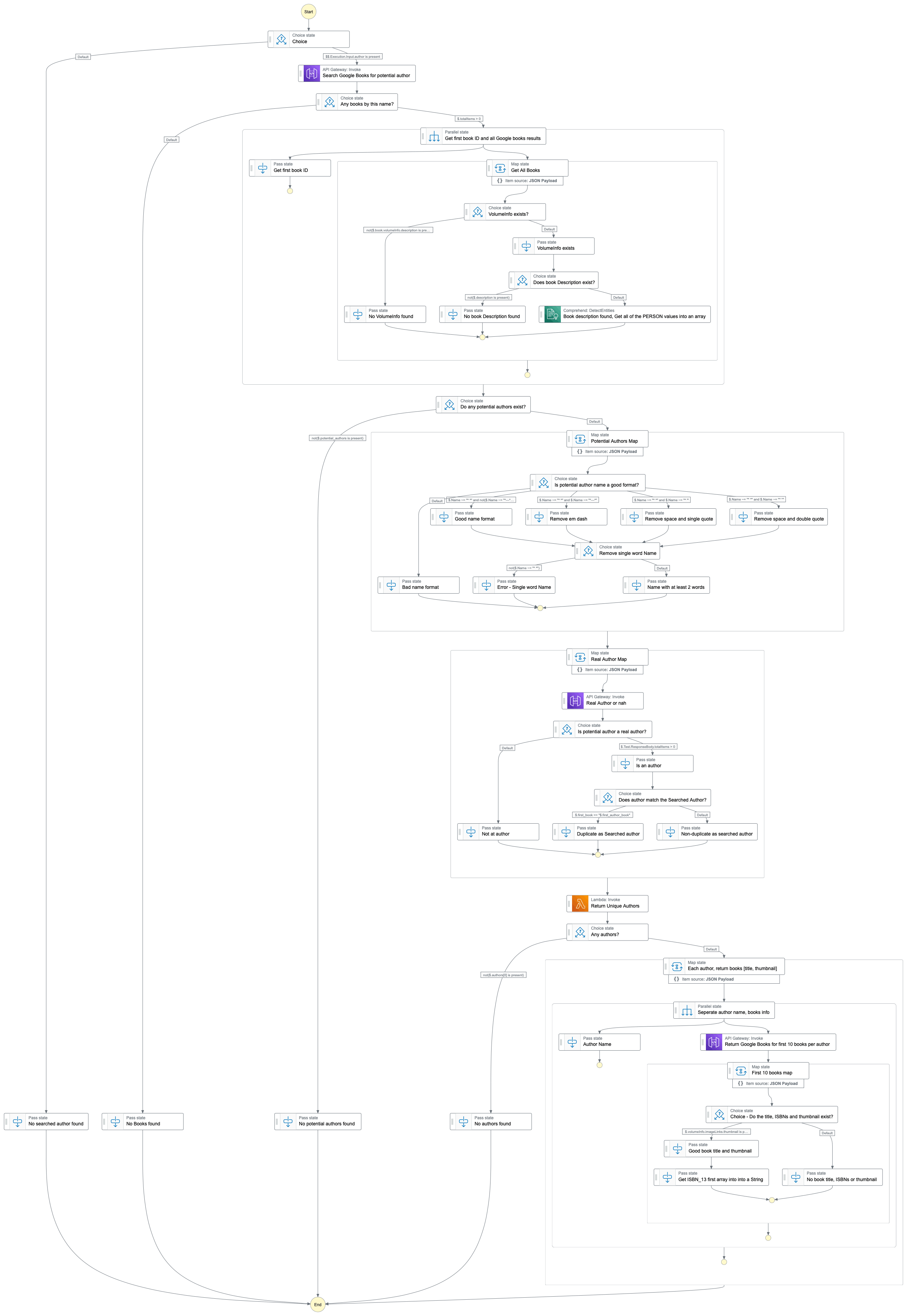
Below is the 5000-foot view of how I process from an author name input, through catching any potential errors, and finally showing any real authors mentioned. This is a massive image, but I wanted to show how I catch errors at each major step in my state machine, and also how I handle potential bad/no data using Choice states.
Current Issues with NextRead
NextRead is a personal project that is not community-driven; I do not have the time or ability to curate a personal recommendation of all mentioned authors. This project was a way to showcase my abilities in software development through building infrastructure as code, crafting an API to serve the data I wanted to display, and ingesting the data in a web app in a somewhat pleasing manner.
NextRead has no way to differentiate between fictional people and real authors with the same name.
NextRead sees book clubs/book groups with an author's name in it (e.g. Reese Witherspoon, Oprah Winfrey, etc.) as mentioned authors.
When NextRead uses the Amazon Comprehend service, some results have names with multi-part first/middle/last names that are broken apart by mistake, and it can lead to two different authors showing in the results.
This project is a joy to work on, looking forward to what comes next in NextRead version 3. For more information, here is the link to the NextRead repository.
Thanks for reading!